
where : ibrtses delphi
Neural networks
disclaimer
the source code of this page may not appear correctly in certain browsers
due to special characters. Have a look at the source of this HTML page
with notepad instead
Intro
Neural networks are great for pattern matching. A pattern may be a bit pattern,
an image, stock quotes, signal samples, or whatever. A NN has first to be trained
to do the matching with samples. It is not able to learn incrementally, meaning
once trained one cannot just another sample, it has to be traineed to do them all
as entiety. As the NN is not a state machine, it has no past and no future. Patterns
that have a timing have to be provided as shiftregister, that the NN has access to
the past values.
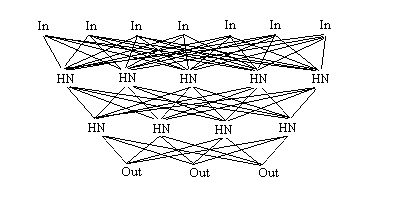
A NN consists of several layers. One layer is the input layer, then there is at least
one hidden layer with the hidden nodes, and finally the output layer. Each layer has
each node connected with all nodes of the previous layer. These connections are
actually weights. Each node sums up the weighted inputs, then calculates an output value
with a nonlinear function which scales +- infinity to +-1. Such a function may be the tanh.
This output value is the propagated to the next layer, or is the output itself.
Before the training the weights are randomly set to values +-0.5 . The NN produces an
output pattern when a pattern is applied at the input. The output is compared with the
wished output and the weights are abjusted accordingly. This is called back propagation.
By repeatedly applying all pattern pairs in a random fashion the results should converge.
If they do not, the size or the structure has to be modified.
implementation
Due to the enormous size of the structure it doesn't make sense to have fixed code.
It has to be optimized for a problem. I'd do it with arrays of single.
var
inputs :array[0..NrOfInputs-1]of single; // the node values
inweights:array[0..NrOfInputs-1,0..NrOfHidden1-1] of single; // the weights
hidden1:array[0..NrOfHidden1-1]of single; // the node values
h1weights:array[0..NrOfHidden1-1,0..NrOfHidden2-1] of single; // the weights
hidden2:array[0..NrOfHidden2-1]of single; // the node values
h2weights:array[0..NrOfHidden2-1,0..NrOfOutputs-1] of single; // the weights
outputs:array[0..NrOfOutputs-1]of single; // the node values
The number of hidden layers and nodes requires a bit of experimenting. Generally
the more the better, but the required CPU time increases exponentially. Start
with two layers and as many nodes on one layer as inputs.
forward propagation
the forward propagation calculates the outputs from the inputs
// calculate one node - h1
procedure propagateinputs(h:integer);
var i:integer;
z:single;
begin
z:=0;
for i:=0 to NrOfInputs-1 do
z:=z+inputs[i]*inweights[i,h];
z:=tanh(z);
hidden1[h]:=z;
end;
// calculate one node - h2
procedure propagatehidden1(h:integer);
var i:integer;
z:single;
begin
z:=0;
for i:=0 to NrOfHidden1-1 do
z:=z+hidden1[i]*h1weights[i,h];
z:=tanh(z);
hidden2[h]:=z;
end;
// calculate one node - out
procedure propagatehidden2(h:integer);
var i:integer;
z:single;
begin
z:=0;
for i:=0 to NrOfHidden2-1 do
z:=z+hidden2[i]*h2weights[i,h];
//no nonlinear mapping
output[h]:=z;
end;
// assumes inputs are set - calculates outputs
procedure propagate_all;
var i:integer;
begin
for i:=0 to NrOfHidden1-1 do propagateinputs(i);
for i:=0 to NrOfHidden2-1 do propagatehidden1(i);
for i:=0 to NrOfOutputs-1 do propagatehidden2(i);
end;
learning - back propagation
The weights are randomly set to +1/2 or -1/2 at startup.
The training of the NN is done by propagating the error back, from the outputs to
the inputs. For a given input, the output is calculated. Then there is an error for
each output. As the weights are known, increase those leading to the right direction,
and decrease those going in the opposite direction. Instead of correcting the weights
such that the right result would be received, change them a fraction of it (1% or such)
Do this for all weights on all layers.
Have a number of sample pattern pairs and apply them randomly while back propagating.
The error should converge to zero after at most a few 10k rounds. Otherwise there
is a different layout of the nodes required.
The back propagation propagates the error back from the output to the inputs.
It then adjusts the weights in the nodes.
untested - as my work on this subject is years back - from memory
procedure backpropagate_onenode(Nodeoutput,NodeWished:single);
begin
node_wished_weighted:=arctanh(NodeWished); // has limited range !!!
node weighted:=arctanh(Nodeoutput); // has limited range, and may be omitted when already stored
Error:=node weighted-node_wished_weighted;
for i:=0 to nodeinputs-1 do begin
inputerror[i]:=Error*nodeweight[i]; '*attenuation' // set attenuation to 0.001 .. 0.1, positive
...
inputweight[i]:=inputweight* ... // this nodes inputs
outputwished[i]:=.... // this nodes inputs nodes output
end;
end;
procedure backpropagate_all;
begin
for i:=0 to outputnodes-1 do backpropagate_onenode(output[i],output_wished[i]);
for i:=0 to hidden2-1 do backpropagate_onenode(hidden2[i],hidden2_wished[i]);
for i:=0 to hidden1-1 do backpropagate_onenode(hidden1[i],hidden1_wished[i]);
end;
notes
the knowledge is stored in the weights. There are almost infinitely many possible
weight configurations leading to a result.
A theorem says : A single hidden layer with infinitely many nodes may solve any problem.
NN are sometimes the last hope for difficult problems. With sufficient time and sufficient
resources you can solve almost any problem. Mostly the time and money runs out before.
For linear problems, the nonlinear mapping may be left away. A single hidden layer is
sufficient then. The structure is similar to a finite impulse response filter then.
A modified back propagation may still be applied. Works great for approximating polynoms
and other stuff.
Feedback is welcome
sponsored links
Delphi
home
last updated: 17.nov.00
Copyright (99,2000) Ing.Büro R.Tschaggelar